Weekly Review June 12 - 17 2022 : MLOps learning and diagrams


Focusing this week on building small ML deployments and making Figma diagrams for different MLOps architectures.
MLOps
Courses and books
I'm looking at doing the new Andrew Ng Coursera Machine Learning Engineering for Production Specialization:
I did the classic ML-cs229 years ago and I always like how clear Andrew Ng's explanations are.
For production data and deployments there are lots of interesting issues with data validation, feature skew, data drift, concept drift etc.
The other learning option is the newly released Designing Machine Learning Systems by Chip Huyen:
- Overview of Machine Learning Systems
- When to Use Machine Learning
- Machine Learning Use Cases
- Understanding Machine Learning Systems
- Machine Learning in Research Versus in Production
- Machine Learning Systems Versus Traditional Software
- When to Use Machine Learning
- Overview of Machine Learning Systems
- Introduction to Machine Learning Systems Design
- Business and ML Objectives
- Requirements for ML Systems
- Reliability
- Scalability
- Maintainability
- Adaptability
- Iterative Process
- Framing ML Problems
- Types of ML Tasks
- Objective Functions
- Mind Versus Data
- Introduction to Machine Learning Systems Design
- Data Engineering Fundamentals
- Data Sources
- Data Formats
- JSON
- Row-Major Versus Column-Major Format
- Text Versus Binary Format
- Data Models
- Relational Model
- NoSQL
- Structured Versus Unstructured Data
- Data Storage Engines and Processing
- Transactional and Analytical Processing
- ETL: Extract, Transform, and Load
- Modes of Dataflow
- Data Passing Through Databases
- Data Passing Through Services
- Data Passing Through Real-Time Transport
- Batch Processing Versus Stream Processing
- Data Engineering Fundamentals
- Training Data
- Sampling
- Nonprobability Sampling
- Simple Random Sampling
- Stratified Sampling
- Weighted Sampling
- Reservoir Sampling
- Importance Sampling
- Labeling
- Hand Labels
- Natural Labels
- Handling the Lack of Labels
- Class Imbalance
- Challenges of Class Imbalance
- Handling Class Imbalance
- Data Augmentation
- Simple Label-Preserving Transformations
- Perturbation
- Data Synthesis
- Sampling
- Training Data
- Feature Engineering
- Learned Features Versus Engineered Features
- Common Feature Engineering Operations
- Handling Missing Values
- Scaling
- Discretization
- Encoding Categorical Features
- Feature Crossing
- Discrete and Continuous Positional Embeddings
- Data Leakage
- Common Causes for Data Leakage
- Detecting Data Leakage
- Engineering Good Features
- Feature Importance
- Feature Generalization
- Feature Engineering
- Model Development and Offline Evaluation
- Model Development and Training
- Evaluating ML Models
- Ensembles
- Experiment Tracking and Versioning
- Distributed Training
- AutoML
- Model Offline Evaluation
- Baselines
- Evaluation Methods
- Model Development and Training
- Model Development and Offline Evaluation
- Model Deployment and Prediction Service
- Machine Learning Deployment Myths
- Myth 1: You Only Deploy One or Two ML Models at a Time
- Myth 2: If We Don’t Do Anything, Model Performance Remains the Same
- Myth 3: You Won’t Need to Update Your Models as Much
- Myth 4: Most ML Engineers Don’t Need to Worry About Scale
- Batch Prediction Versus Online Prediction
- From Batch Prediction to Online Prediction
- Unifying Batch Pipeline and Streaming Pipeline
- Model Compression
- Low-Rank Factorization
- Knowledge Distillation
- Pruning
- Quantization
- ML on the Cloud and on the Edge
- Compiling and Optimizing Models for Edge Devices
- ML in Browsers
- Machine Learning Deployment Myths
- Model Deployment and Prediction Service
- Data Distribution Shifts and Monitoring
- Causes of ML System Failures
- Software System Failures
- ML-Specific Failures
- Data Distribution Shifts
- Types of Data Distribution Shifts
- General Data Distribution Shifts
- Detecting Data Distribution Shifts
- Addressing Data Distribution Shifts
- Monitoring and Observability
- ML-Specific Metrics
- Monitoring Toolbox
- Observability
- Causes of ML System Failures
- Data Distribution Shifts and Monitoring
- Continual Learning and Test in Production
- Continual Learning
- Stateless Retraining Versus Stateful Training
- Why Continual Learning?
- Continual Learning Challenges
- Four Stages of Continual Learning
- How Often to Update Your Models
- Test in Production
- Shadow Deployment
- A/B Testing
- Canary Release
- Interleaving Experiments
- Bandits
- Continual Learning
- Continual Learning and Test in Production
- Infrastructure and Tooling for MLOps
- Storage and Compute
- Public Cloud Versus Private Data Centers
- Development Environment
- Dev Environment Setup
- Standardizing Dev Environments
- From Dev to Prod: Containers
- Resource Management
- Cron, Schedulers, and Orchestrators
- Data Science Workflow Management
- ML Platform
- Model Deployment
- Model Store
- Feature Store
- Build Versus Buy
- Storage and Compute
- Infrastructure and Tooling for MLOps
- The Human Side of Machine Learning
- User Experience
- Ensuring User Experience Consistency
- Combatting “Mostly Correct” Predictions
- Smooth Failing
- Team Structure
- Cross-functional Teams Collaboration
- End-to-End Data Scientists
- Responsible AI
- Irresponsible AI: Case Studies
- A Framework for Responsible AI
- User Experience
- The Human Side of Machine Learning
Currently working through the MadeForML MLOps course. It's fairly small and covers lots of production processes and concepts and libraries.
Python dependency management is ... a bit messy. The course project could not be installed with Python 3.10 which I was using.
3.7.10 is recommended by Goku Mohandas but ... my new M1 cannot build numpy with pyenv and Python 3.7.10!
Python 3.7.13 fixed the problem. I filed an issue and Goku has updated the course now.
These versions of Python work fine:
3.7.13, 3.8.13, 3.9.11 and 3.10.3 all work fine on my Intel mac. The GCC solution was not a viable one for me as it caused issues with pip modules that were built with clang. github
Python ML tools
Used Optuna for hyperparameter optimization
Used cleanlab which finds labelling errors in real world datasets. It can discard suspect noisy labels during training.
Set up a [[Weights and Biases]] account and setup tracking. The MadeForML course uses (local) MLflow. I wanted to dive into Weight and Biases which is much more advanced than MLflow. The basics were easy, there's lots more to learn though.
Used snorkel to define slice functions and select results, calculate metrics. This is for sampling segments of your data and getting training metrics for that slice. Useful to see how your model is performing on specific problem areas.
The Snorkel Team is now focusing their efforts on Snorkel Flow, an end-to-end AI application development platform based on the core ideas behind Snorkel
Everybody is building an end-to-end platform now! ML in production has been rapidly evolving, and now patterns of usage are settling down. That's why everybody is building full platforms now. We are at that stage.
Studying Seldon for deploying ML in Kubernetes with monitoring and metrics. I didn't yet install it locally to
Diagrams
My Figma skills are slowly improving. I need to spend more time on these.
I made a diagram for a Kubeflow pipeline, tracked with MLflow deploying with seldon.
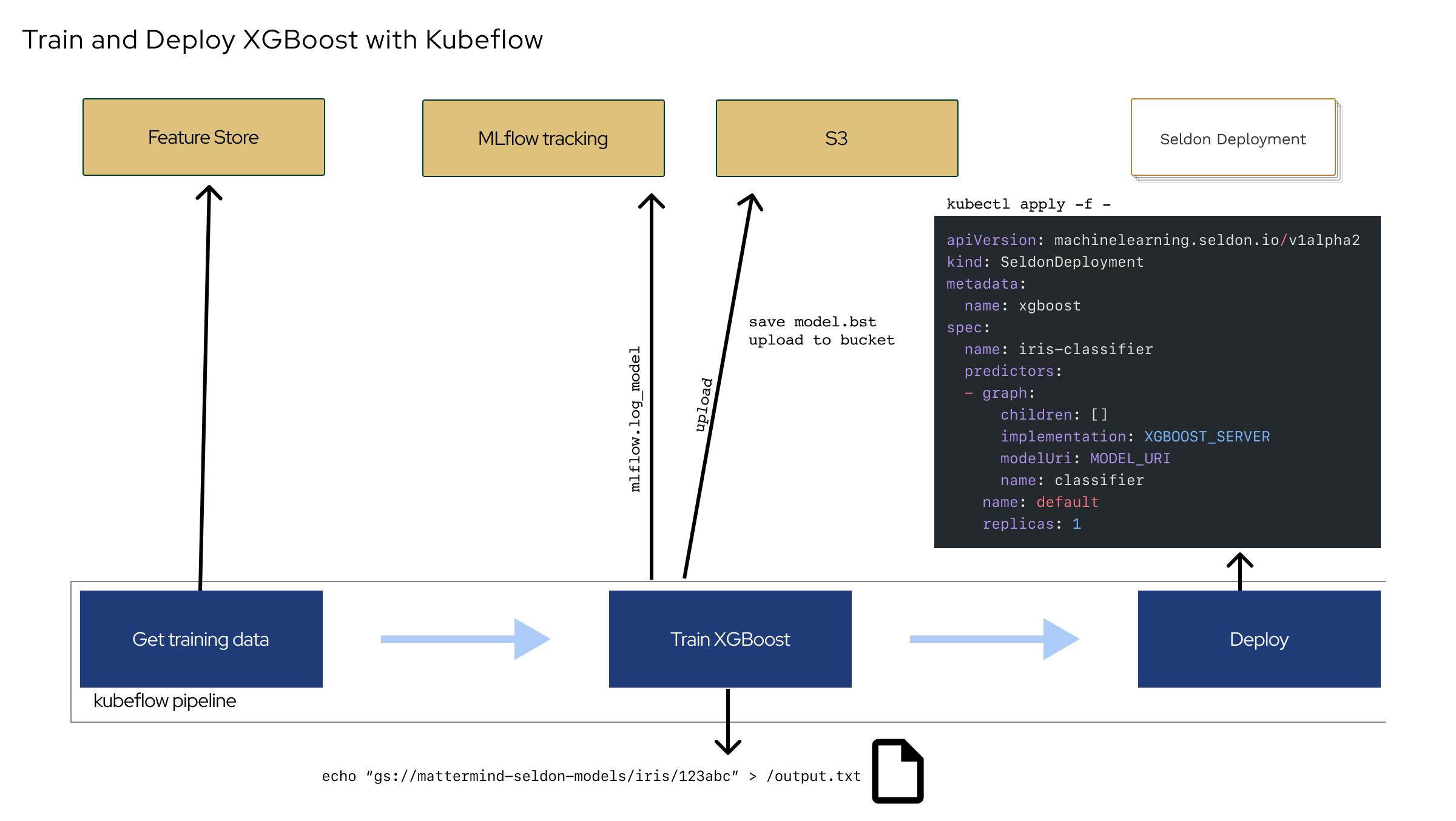
It still looks complex, doesn't communicate the work process yet. This is what the diagrams are for: increasing understanding or identifying confusion.
Links of the week
GHGSat Montreal GHG emissions tracking via satellite
If I'm gone
A template for "A cheat sheet for if I am somehow incapacitated." github.com/christophercalm/if-im-gone/blob/..
Typer
typer.tiangolo.com [[python]] [[cli]] generator using decorators and python type hints
Though of course Click is very nice.